
Welcome! Our “Unlocking AI potential in e-commerce and online business” series aims to provide basic guidance on applying AI (Artificial Intelligence) in businesses which use the internet as a primary source for delivering value to their customers.
In the first three articles we focused on AI essentials – terms, buzzwords, project management and data selection. Now, it’s time to dive a little deeper. The number of companies which have adapted AI (or have at least tried to) has been growing steeply in the past few years.
- R&D spending has dramatically surpassed advertising spending, according to this article, published by Harvard Business Review in May this year
Following this trend, more and more questions emerge regarding usage of AI:
- Interpretability of machine learning
- AI and ethics
- Reliability and fairness when classifying people data
Let’s have a look at the first of these; enjoy your reading!
Are you new to AI and Machine Learning? If so, we recommend the first article in our “Unlocking AI potential in e-commerce and online business” dealing with basic concepts.
Behind the scenes
In the last article in our “Unlocking AI potential in e-commerce and online business” series we already suggested how to turn abstract business knowledge into machine learning variables. Using the Fictional Online Fashion Store example, we illustrated how to think about data sources when making a tool for website content personalization and product recommendation. Imagine we successfully trained the model. Now, why does the model behave the way it does? Besides the input data, it depends on the model architecture we have chosen.
Similarity matrix and clustering
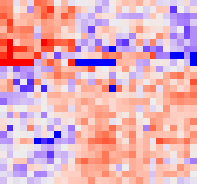
From one point of view, we can think of intelligence as a process of labeling input data. Each millisecond, our brain processes perceptions from our senses (data) and assigns them a category or state based on our knowledge and historical experience. Mathematically speaking, it’s basically a search for arguments which maximize a given probability function. If we choose associative modeling as our machine learning strategy, we can represent this probability function using a heat map or network graph.
The following picture illustrates how a simple similarity matrix may look from the inside. The machine learning of such a model could be done as follows: if a customer purchases product 1 together with product 2, we increase the value of the matrix at coordinates [1, 2] (and [2, 1] accordingly). Each value in the matrix then represents a relevance between products on corresponding indices based on historical purchases. A bigger value means that a customer that has already added product 1 to his cart, will be more likely to buy product 2 as well if we offer it to him.
The best combination of products to offer is represented by indices of maximum values for corresponding rows.
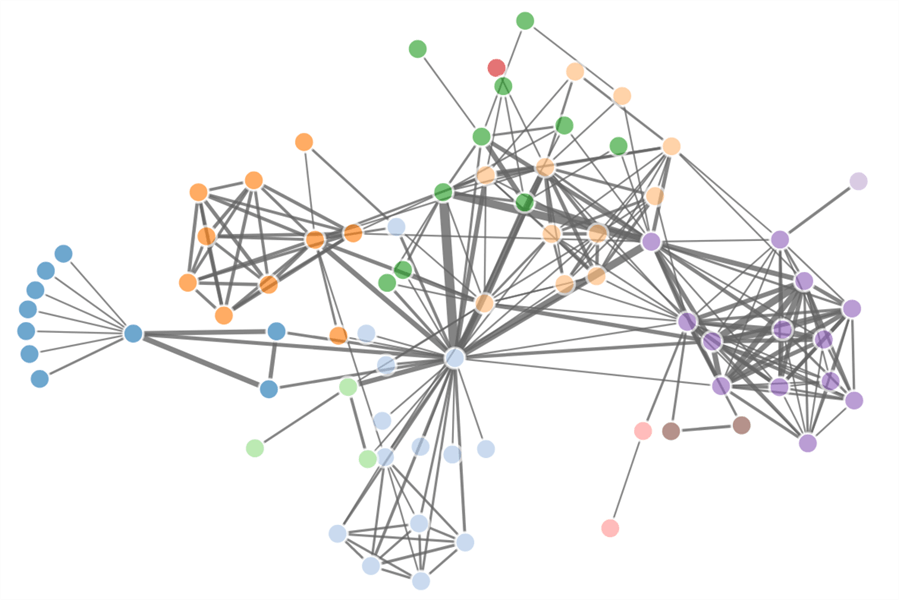
A slightly different visualization could be made using a graph to capture relationships between products. Each point in the graph will represent one particular product. In this case, we can think of machine learning as moving points in the graph closer or further apart using data about purchases. After some time, points will form clusters suggesting which products should be offered together.
Random forest
Another method our brain uses to make decisions is a subconscious creation of stereotypes. When we experience the same situation with the same result over and over, the probability of this sequence of events surpasses an imaginary threshold. If this occurs, our brain creates a rule which replaces computation of probability for this case in the future. We can think of it as an optimization of our brain computation capacity. In other words, stereotypes help us to make decisions more quickly and efficiently. A machine learning counterpart of this principle is a random forest.
A random forest is nothing more than a set of several IF-THEN decision trees. What is interesting is the process of how these trees and rules are made during training. The result of the machine learning process is determined by several hyperparameters. The most important ones are:
- amount of decision trees in the model
- maximum depth of each tree
- minimum amount of data points required to split an internal node
- minimum amount of data points required to be a leaf node
During the machine learning process, an algorithm looks for features and values which could be used to split data points into tree branches while meeting conditions specified by chosen hyperparameters.
How to deal with data selection and knowledge representation in AI projects? You can find a few tips in the third article in our “Unlocking AI potential in e-commerce and online business” series!
For instance, when predicting next purchases, we can think of this machine learning process as splitting customers into segments based on historical interactions or the amount of recent purchases.
The limit for the minimum amount of data points in tree branches and leaf nodes is actually the encoded probability threshold mentioned earlier. The maximum tree depth represents the level of granularity and the amount of decision trees implies how many different problem solutions will be combined into the final result.
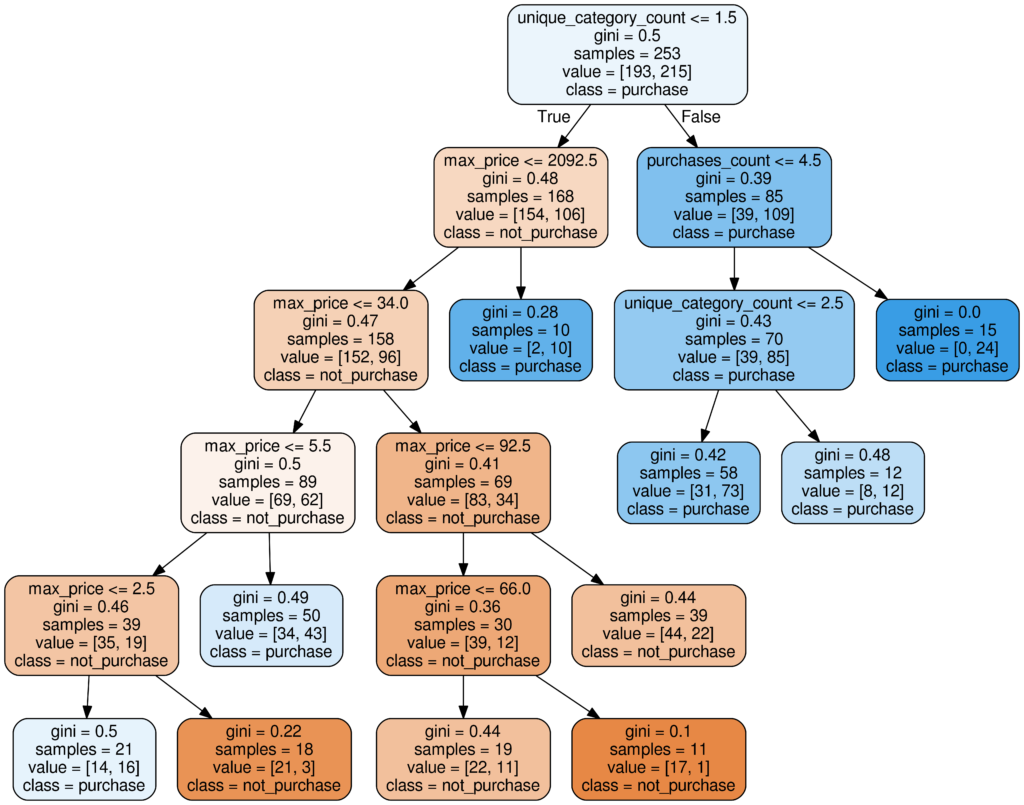
Therefore, the output of the trained model corresponds to relationships between data points and internal rules and splits reveal important features and threshold values. That’s why we can use a random forest not only as a final solution, but also as a very efficient data exploration method in the initial steps of AI prototyping. Strong features and rules could be extracted from the model and used on their own as a decision support tool.
Neural network
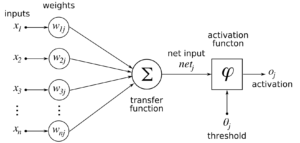
The first model of an artificial neuron was created by Warren McCulloch and Walter Pitts in 1943. It was a simple mathematical representation of a signal transfer between real neurons in the human brain.
Since then, multiple neural network architectures have been made, nevertheless, the core principle has remained the same. Perceptions from senses are transformed into a signal which causes a chain activation of particular neurons. Neuron activity is determined by a transfer function and its arguments (weights), which are formed during the learning process.
Neural networks are usually considered a black box. The main reason for that is the fact that it is extremely hard to explain why particular neurons have been activated after the learning process when a particular input is presented to the network.
To some extent we can use biology (or neuroscience) for inspiration. When studying the human brain, scientists measure the activity of different parts of the brain in response to a particular perception. Likewise, we can log activation of artificial neurons and explore which part of the neural network is responsible for a specific decision.
How to successfully execute AI-related projects? You can find a few tips in this article in our “Unlocking AI potential in e-commerce and online business” series!
The question is, could we use such information to estimate the behavior of the neural network in the future?
This topic is still being studied. For example, a recent study conducted by Google AI scientists examines the possibility of using attribution modeling and neuron activation monitoring to create human-readable insights about the decision-making process of the neural network during image classification. The method transforms the importance of image pixels (input neurons) into the importance of image features, for example how important is a “stripe” feature for the neural network when classifying a zebra picture.
I know what is inside the AI, what next?
One reason why interpretability of machine learning models is becoming a big issue is the increasing interest in the discussion about the ethical aspects of AI. What can we do to prevent the development of a biased and unfair mathematical model? Don’t miss our next article!
About the author
My name is Ondřej Kopička and I help companies automate data analysis.
Does the volume of your data exceed the capacity of your analysts? Then we should talk.
Connect with me on LinkedIn: https://www.linkedin.com/in/ondrej-kopicka/



